New Yorker Short Story Recommender
Abstract
The goal of this project is to build a recommendation system for New Yorker short stories. This recommender might be of use to any New Yorker fiction reader who wants to find similar stories based on topic, writing style, or author.
Design and Data
The data was scraped from the fiction section of The New Yorker website and includes 944 short stories by 333 different authors from 2001 to 2022. The word counts for the stories range from 593 to 16,122 with an average word count of 5,717 words.
The initial data included the story’s url, author, title, date of publication and text.
Algorithms
Preprocessing
- Removed text, punctuation and special characters
- Removed stopwords and lemmatized text with spaCy
- Used spaCy to extract nouns, verbs, and adjectives from the text
Topic Modeling
- Tried several techniques (NMF, LSA, LDA, CorEx), but ultimately settled Non-Negative Matrix Factorization (NMF) with TF-IDF vectorizer.
- Used NMF with TF-IDF on nouns from each text to create 6 topics based on top terms:
- Topic 1: City/School (top terms: apartment, student, class, train, office, hotel, bar, painting, building, dinner)
- Topic 2: Country/Nature (top terms: road, river, wind, stone, sun, field, sea, horse, grass, sky)
- Topic 3: Dude/Bro (top terms: kid, guy, mom, shit, dad, cop, brother, ass, yard, son)
- Topic 4: Motherhood/Pregnancy (top terms: baby, nurse, doctor, sister, hospital, diaper, stroller, skin, belly, couch)
- Topic 5: Animals/Suburbia (top terms: dog, doctor, leash, porch, gate, yard, animal, mask, paw, tail)
- Topic 6: Family/Village (top terms: husband, daughter, son, brother, sister, law, grandmother, doctor, village, marriage)
Clustering
- Used spaCy to get noun, verb, adjective and adverb counts for each story, as well as average sentence length
- Used LexicalRichness to find the Type-Token Ratio for each story
- Used PCA to reduce these features to 2 dimensions
- Performed k-means clustering, looking at inertia to choose 6 clusters
- Assigned each story to a “style group” cluster
Recommender
Given a short story, the recommender can return a list of short story recommendations based on the cosine similarity of topics, style group, and author. Users can also adjust the weights of these criteria based on their own preferences.
Tools
- Selenium, BeautifulSoup
- Numpy, Pandas
- sklearn
- spaCy
- LexicalRichness
- Seaborn, Plotly
Notebooks:
- Web Scraping
- Data Cleaning
- Preprocessing with spaCy
- Topic Modeling
- Clustering
- Recommendation System
Results
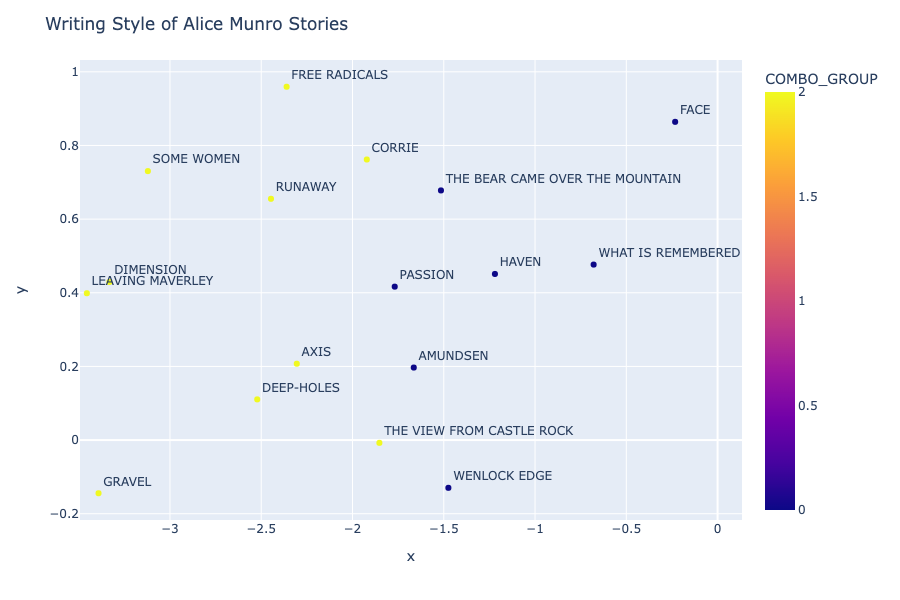
Clustering to find writing style of each short story (using Alice Munro stories):
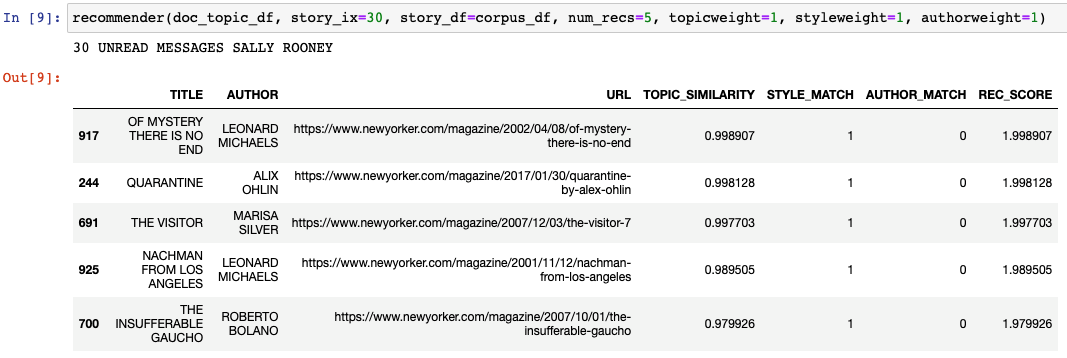
Recommender in action–recommending 5 short stories similar to “Unread Messages” by Sally Rooney:
See GitHub for the code notebooks and a .pdf file of the Google Slides presentation about the project!